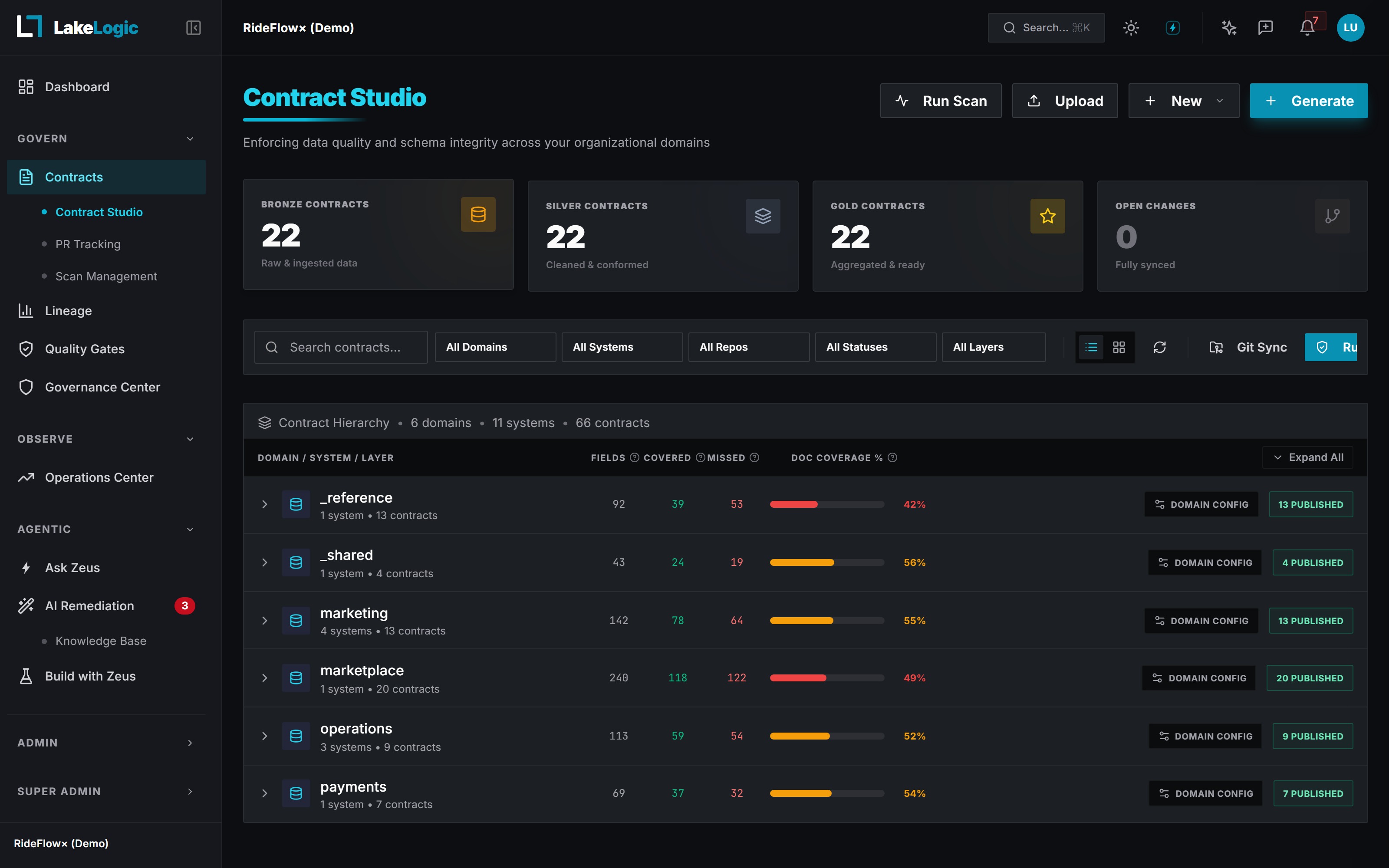
The Git-native Data Contract Platform
Bad data breaks production. Trust every data change before it ships.
Automatically enforce schema, data quality, ownership, and compliance in every pull request before deployment.
Powered by LakeLogic. Open source, Apache 2.0
your data never leaves your lakehouse.
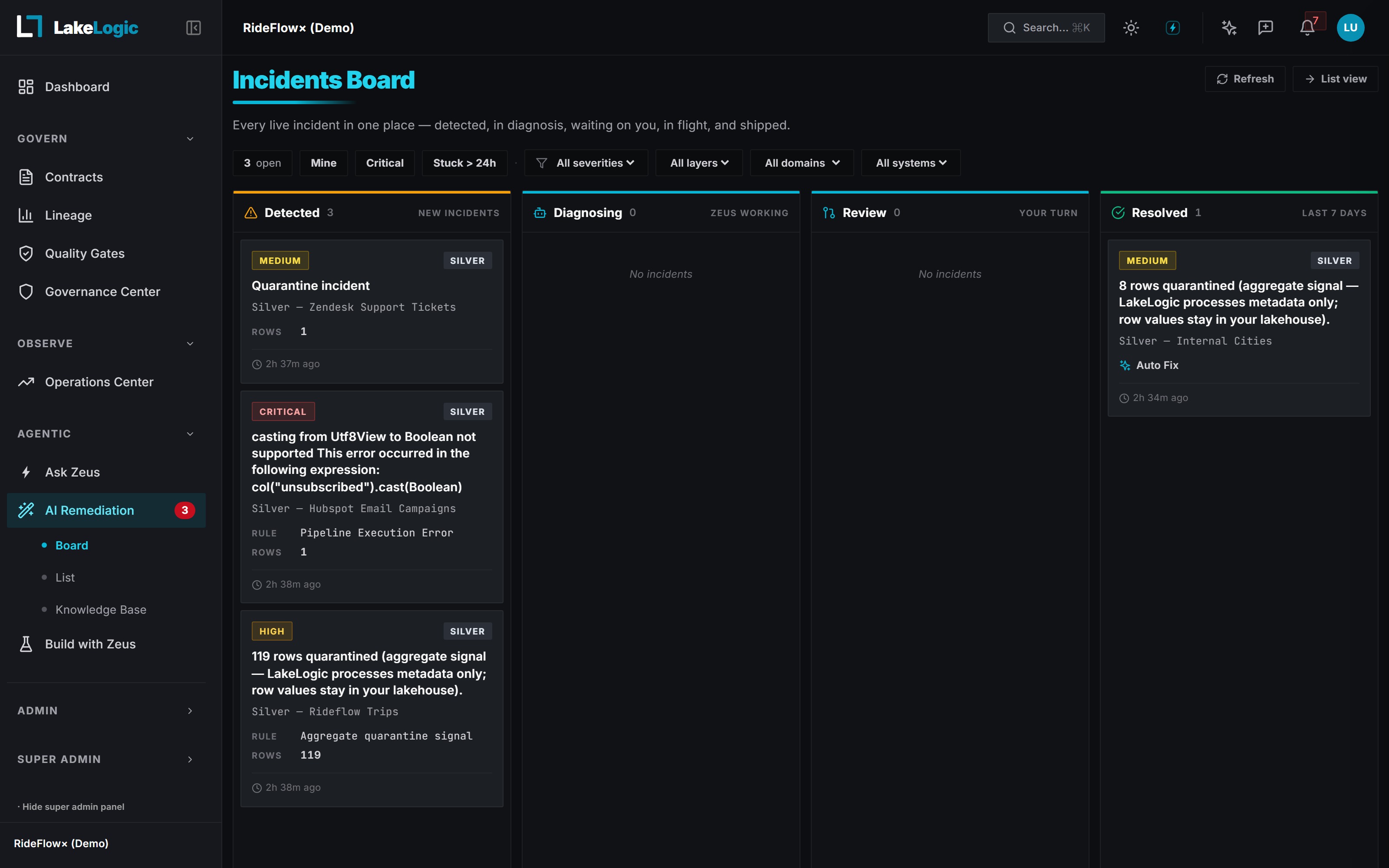
The closed loop
One contract, enforced end to end.
Define trust once. LakeLogic enforces it at the PR, catches what slips at runtime, and when something breaks, Zeus drafts the fix. Every incident it resolves makes the next one faster.
Author the contract
Schema, quality, ownership, and compliance. Versioned YAML in your repo.
Block it at the PR
Contract-breaking changes fail the check before they merge, whether human or agent.
Catch bad rows at runtime
Rows that violate the contract route out before they reach production.
Zeus drafts the fix
The agent diagnoses in context and opens the fix as a human-approved PR.
Every fix Zeus ships feeds your incident memory, so the loop gets faster the longer it runs.
Portable by design
Own your contracts. Not your vendor.
Most governance platforms keep your rules in their database. LakeLogic generates portable contracts that live in your codebase, reviewed in pull requests, and yours even if you stop using LakeLogic.
Version-controlled
Every rule is a file in your repo. Every change is a diff you can review, blame, and revert.
Reviewed in PRs
Governance happens where engineering already happens, in the pull request, not a separate console.
Portable by design
Your contracts stay valuable even without LakeLogic: plain, human-readable YAML you own. No export, no lock-in.
Zero-egress
We read run metadata, never your data values. Your warehouse stays your warehouse.
Auto-generated · human-readable · owned by your team
version: 1.0.0
info:
title: Silver - Rideflow Trips
domain: marketplace
system: rideflow
target_layer: silver
primary_key: [trip_id]
source:
type: delta
path: '{bronze_path}/bronze_rideflow_trip_completed'
load_mode: incremental
watermark_strategy: pipeline_log
quality:
row_rules:
- name: positive_spend
sql: "fare_amount >= 0"
- name: valid_rating
sql: "rider_rating BETWEEN 1 AND 5"
slo:
freshness: { max_delay_minutes: 120 }
quality: { min_good_ratio: 0.92 }
compliance:
sensitivity: Internal
gdpr: { applicable: true, legal_basis: legitimate_interest }
retention: P90DThe contracts are an asset you keep, not a subscription you rent.
The leverage compounds where your team already works: in Git, in CI, in the pull request you already review. LakeLogic generates and enforces them; their value doesn’t depend on a renewal.
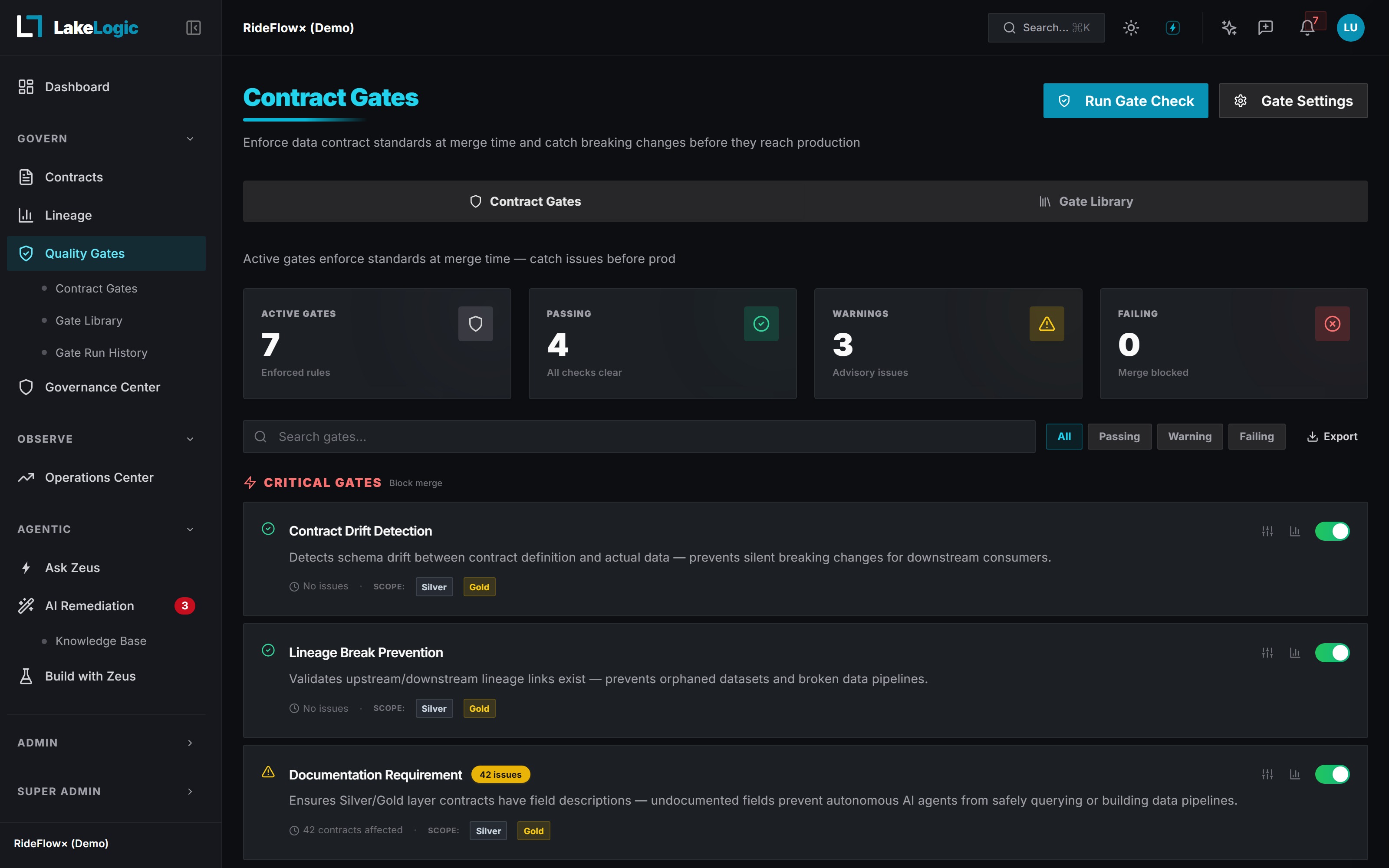
Enforcement, not documentation
Caught in the pull request. Not production.
LakeLogic runs as a required check on every pull request. A change that would break a contract (a dropped column, a relaxed rule, a missing owner) fails the gate and blocks the merge. Bad data never gets the chance to ship.
- Breaking-change & schema-drift detection
- Blast radius: names the downstream tables at risk
- Runs in GitHub Actions, GitLab CI, or any runner
✗ silver_rideflow_trips: contract violation
• breaking change: column rider_rating removed
required by gold_dim_driver_scorecard, gold_fact_trip_daily_kpis
• quality rule valid_rating references a missing column
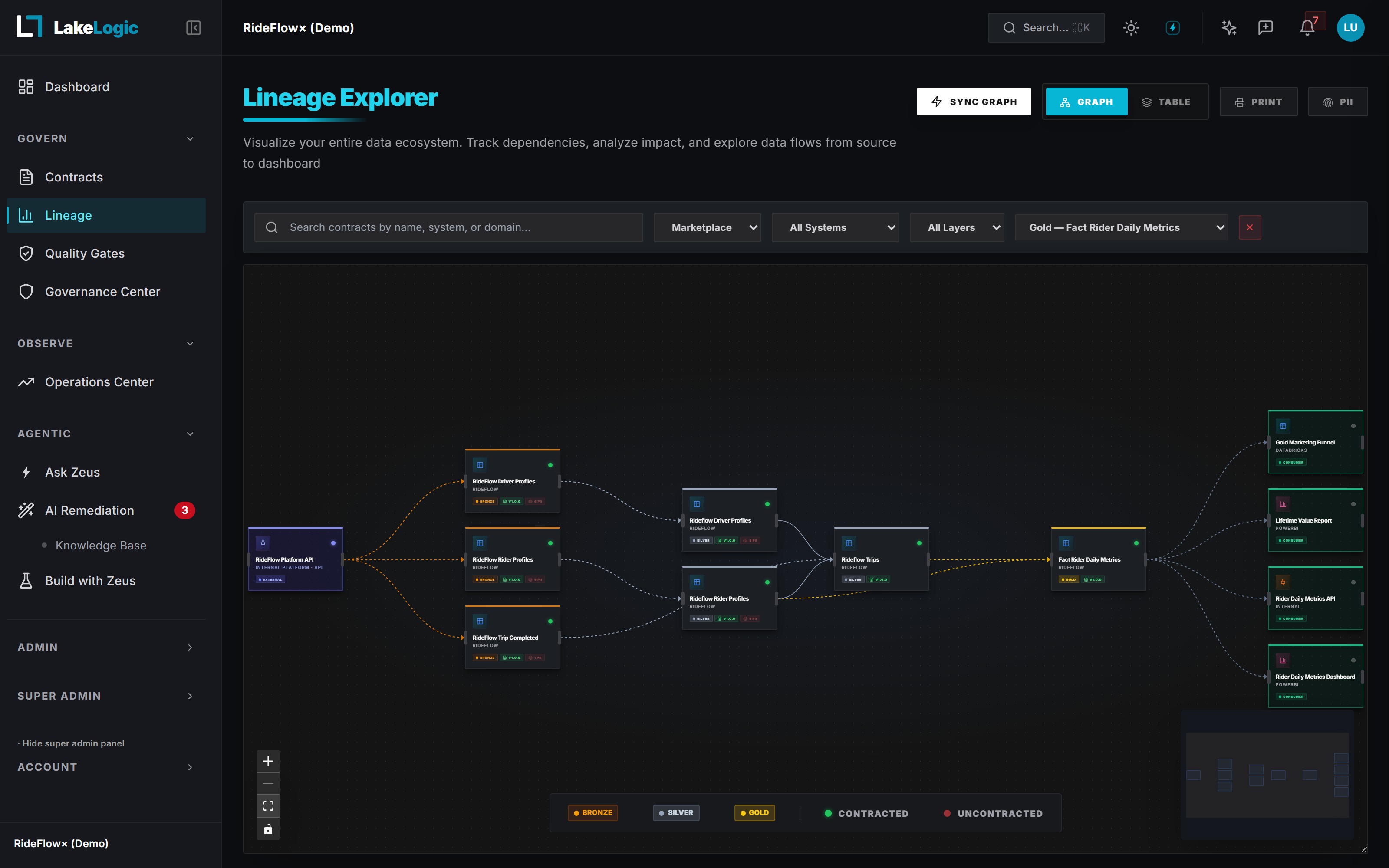
Where LakeLogic sits
Between observability and governance. Contract-first.
Observability
Monte Carlo · Bigeye · Anomalo
Watches pipelines after they run. Detects anomalies once they've already hit production.
- ·Post-hoc detection
- ·You learn after the dashboard breaks
- ·No PR-time enforcement
AI Incident Resolution
LakeLogic
Defines trust before the run, enforces it during the run, proves it after. Across every engine.
- Block unsafe changes in PRs
- Quarantine bad rows at runtime
- Zeus diagnoses incidents and reduces MTTR
- Polars · DuckDB · Spark · Delta · Iceberg
Governance & Catalog
Collibra · Atlan · Informatica
Documents pipelines after they exist. Heavyweight rollouts, separate from engineering workflow.
- ·Documentation-led
- ·Lives outside the PR workflow
- ·6-month rollouts, 6-figure prices
Most teams buy separate tools for detection, governance, and remediation. LakeLogic compresses the three jobs into one operating layer, built around the contract, not the dashboard.
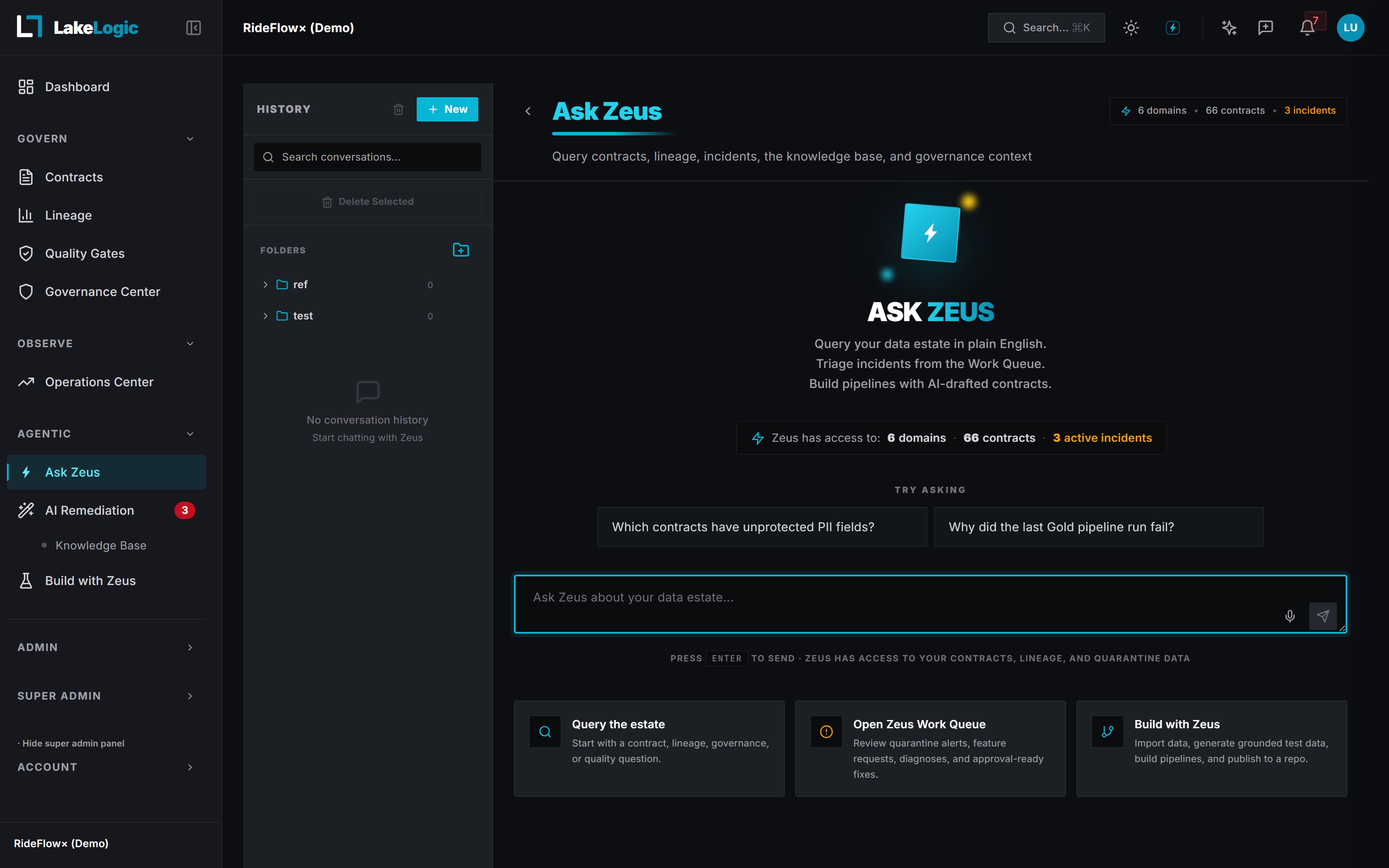
How Zeus Learns What's Correct
Contracts teach Zeus your standards.
Every contract (quality rules, owners, SLAs, PII flags) is one more thing Zeus knows about your data. Define it once in a visual editor or plain YAML; Zeus uses it to detect drift, route quarantines, and explain incidents in your team's vocabulary, not generic ML.
Bad data never reaches your dashboards. Quarantine routing on every pipeline run
Business users and engineers edit the same contract. Visual editor for ownership, SLAs, and PII tags; plain-text for code reviews
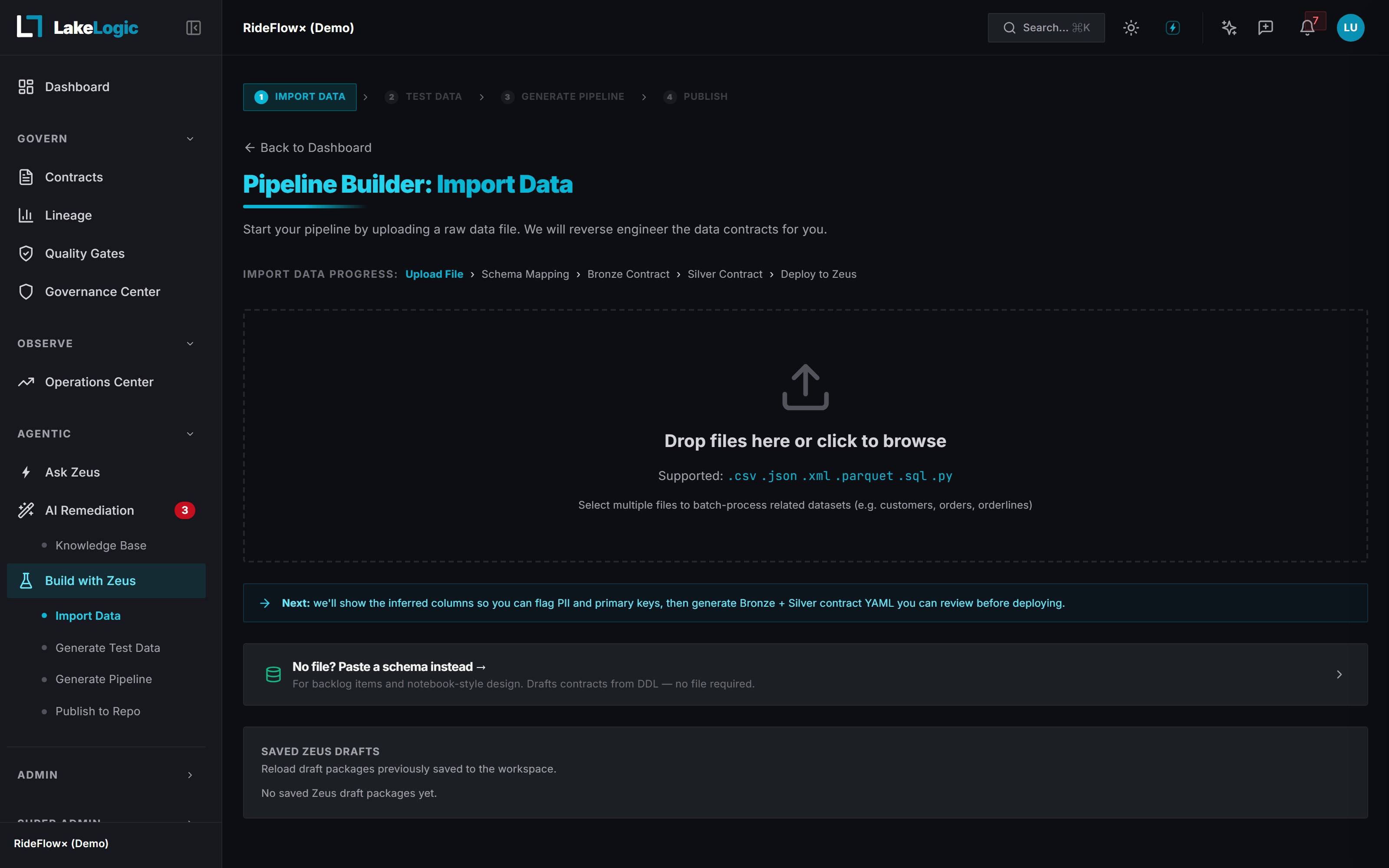
Generate a contract in minutes from code you already have. Zeus reads your pipelines (AI-assisted)
Change reviews built into your workflow. Git + pull requests, no new tools to learn
Open standard, works with your existing tooling. Plain YAML, no proprietary format
Runs on
One contract. Every engine you already run.
 Spark
Spark DuckDB
DuckDB Polars
Polars Databricks
Databricks Fabric
Fabric Snowflake
Snowflake BigQuery
BigQuery Redshift
RedshiftNative on Polars, DuckDB, and Spark; runs anywhere PySpark does. Warehouses read and write today, with native SQL pushdown on the roadmap.
Company Brain
Every incident makes Zeus smarter.
The first time Zeus sees an incident, it reasons from your contracts, lineage, and run history. Every time after, it recalls the fix your team already approved. The knowledge compounds, and it stays in the platform when people move on.
Stripe webhook schema drift
field customer_email changed shape upstream.
Zeus ROI
What that’s worth to your team.
Move the sliders to match your team. The number on the right is the engineer-hours Zeus reclaims every year.
Your setup
A healthy 25-pipeline team typically sees 10-40 incidents/month. The pipelines slider above just sets context.
Assumption: Zeus diagnoses ~80% of incidents to a resolution in under an hour. Untouched incidents fall back to your current time-to-resolve. Adjust your hourly cost to match fully-loaded salary + benefits.
Annual impact
Reclaimed eng cost / year
$144,000
≈ 1,440 engineer-hours reclaimed, 0.7 FTE of capacity returned to feature work.
360
$216,000
$72,000
1,440
Estimates only. Real savings depend on incident mix, on-call structure, and how quickly your team adopts Zeus suggestions.
Have questions? Most teams do.
The short answers below cover what we get asked most often. If you don't see yours, the founders read every inbound, so reach out directly.
Talk to the foundersBuilt for the security team too
Your data never leaves your lakehouse. Period.
Metadata only
We process schemas, lineage, rule names, row counts. Never row-level data. Your warehouse stays your warehouse.
Open source core
The runtime engine is Apache 2.0 on GitHub. Audit the code. Self-host the OSS forever. No vendor lock-in by design.
GDPR-ready primitives
PII flagging, masking strategies, and right-to-be-forgotten erasure are first-class, built into the contract, not bolted on.
SOC 2 on the roadmap
Pre-launch and pursuing SOC 2 Type II. Until then: minimal data surface, regional deployment, signed DPA on request.
Need a security questionnaire, DPA, or architecture deep-dive? Contact us. The founders read every inbound and reply within a business day.
Two Products · One Vision
Give your data platform a memory.
Join the data teams building a company brain for their data platform: contracts, lineage, and every resolved incident, remembered.
Contact UsThe declarative, executable contract engine. Apache 2.0, free forever, runs on Polars, Spark, or DuckDB.
View on GitHubObservability, Zeus AI, and enterprise governance, fully managed. Zero infrastructure to run.
Talk to us about Cloud